

Place à un outil pour optimiser son seo en ce début février 2014. La maison botify vient de lancer en cette mi-janvier 2014 sa plateforme d’analyse de site web en mode saas. J’avais pu écrire un article sur le sujet et notamment sur l’analyse de logs voilà quelque temps. J’ai testé une de leur offre, celle du crawl d’urls du site . Cette plateforme pratique vous permet sans aucune connaissance technique de collecter une batterie de données sur un site web. L’intérêt de cet outil est d’optimiser un site par l’amélioration de la qualité de son architecture , de ses pages (technique de balisage des pages ), et de son contenu (du linking interne et externe, duplication, temps de chargement). Bien sûr ces différents éléments sont intrinsèquement liés les uns aux autres pour fournir un tout cohérent pour les crawlers et le visiteur final !
Ergonomie et Interface simple
Interface et ergonomie de botify
Une interface simple et épurée donne accès en quelques clics au crawl à effectuer sur le site, le menu de navigation central est constitué par 8 accès , avec un choix de représentation des données sous forme tabulaire type tableur ou graphique circulaire. L’affichage est restitué par une ergonomie glissante des rapports depuis la partie droite de l’écran. L’accès du menu de navigation offre les fonctionnalités suivantes :
- Dashboard : 3 récapitulations du temps, des codes serveurs et du balisage des pages.
- Distribution : urls par profondeur depuis la homepage, indéxées ou pas, renseignées no follow, par type de code (html)
- Performance : répartition des urls par temps de chargement
- http codes : énumération succès par (2xx –), redirection (3xx), erreur client (4xx) ou serveur (5xx)
- html tag : Unicité ou duplication du balisage des pages , (titre, H1, Méta)
- Canonical : Marquage des url par l’attribut canonique
- Inlinks : Suivi du Typage des liens internes hypertextes en follow no follow
- Outlinks : comparatif linking interne et externe selon follow ou no follow.
Menu navigation Botify
Architecture du site
Le crawler Botify restitue la profondeur d’accès depuis la page d’accueil. Ce rapport est utile pour identifier le nombre de clics à opérer pour atteindre une page. L’idéal est d’avoir une navigation bien organisée afin de permettre un accès le plus rapide au contenu. De plus, les crawleurs allouent un certain « budget » en temps passé par site , plus les pages auront un accès profond, moins leur indexation sera efficace selon le degré d’intérêt des robots accordé au site (fraîcheur, notoriété, autorité, pertinence).
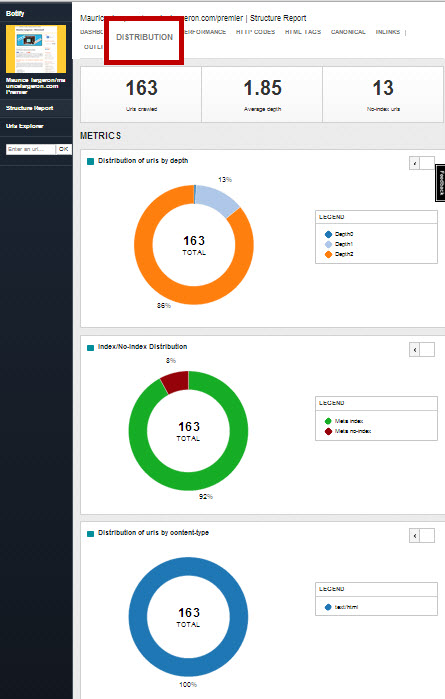
Distribution depuis la page d’accueil et indexation
Un taux de profondeur moyen est calculée, un état de sur le nombre d’urls non-indexées et le type de langage du contenu (ex :html)
Qualité des pages
Balisage html
Les attributs principaux seo html des pages sont restitués avec précisément le titre – la H1 – Hn (emplacement des mots clés de la page) , la méta description (base des snippets pour le moteur Google dans ses pages de résultats) . Pour les urls collectées , un détail est donné sur chacune des balises avec par exemple une liste des urls ou les H1 sont manquantes.
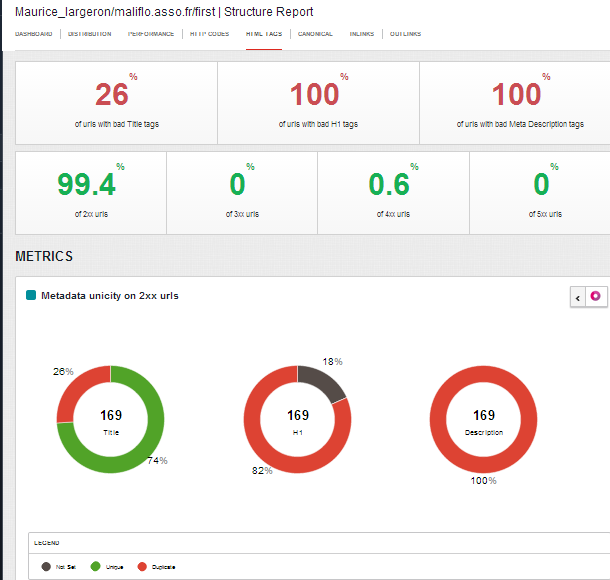
Balisage des pages
Optimisation du contenu
Netlinking Interne des pages
Les liaisons entre pages de même contenu au travers du site passe par ces liens hypertextes dont l’attribut no-follow fut instauré afin d’indiquer au crawler de ne pas suivre leur chemin, le « do-follow » (son opposé) existant par défaut . Des stratégies de link sculpting furent ainsi bâties pour optimiser le poids des pages (link Juice) afin d’améliorer son page rank .
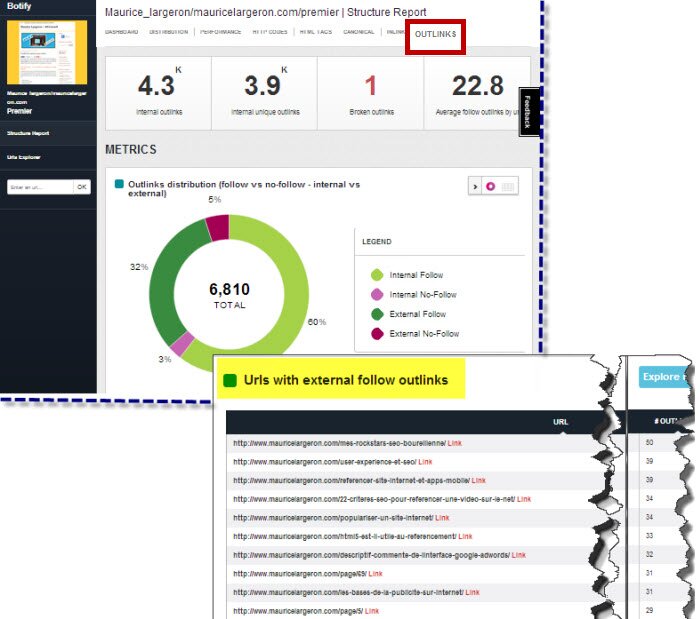
Liens internes & externes (no vs do follow)
En outre , et afin d’apporter une cohérence lexicale et sémantique , ces liens sont aussi utilisés avec un paramétrage de mots clés dans leurs ancres. Ces techniques d’optimisation font couler beaucoup d’encre, c’est le cas de le dire. Les développements successifs des filtres de l’algorithme Google ont changé la donne au fil des années.
Duplicate content
Les robots des moteurs de recherche n’aiment pas les contenus dupliqués, c’est-à-dire les urls qui aboutissent au même contenu. Ces urls sont parfois générées par les plateformes (cms, blogs, e-commerce) lors d’une mauvaise pagination, par UGC (ajout de commentaires) , attributs produits etc.. Il faut donc indiquer l’adresse canonique unique sur ces pages dupliquées. Botify renseigne sur l’état de cette canonisation sur l’ensemble des urls avec un détail du pointage des urls canonisées dans leur état similaire ou différent.
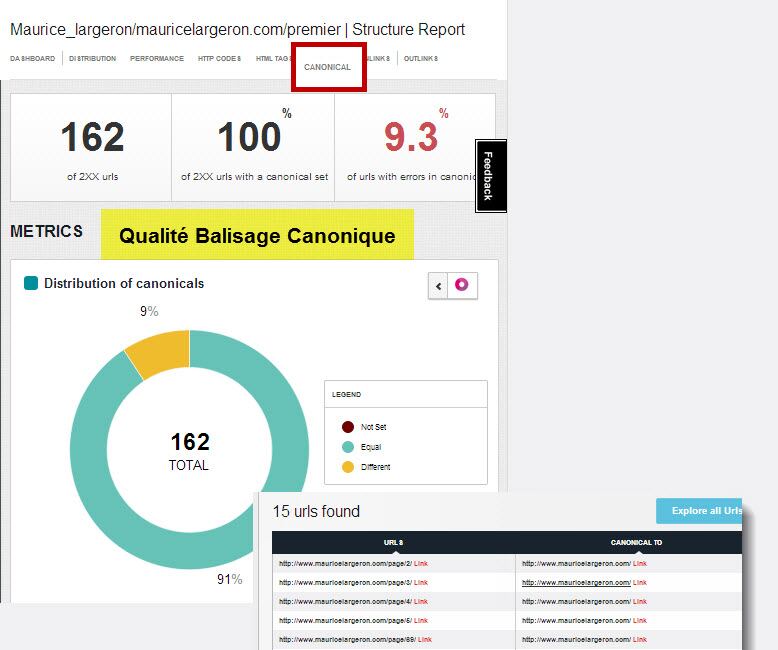
Marquage canonique des urls
Temps de chargement des pages
Moins d’une seconde est le temps généralement accepté comme correct pour une page. Ici l’échelle de mesure va de -500 millisecondes (très rapide) à 2 secondes (très lent). Un temps moyen général est indiqué. Cet aspect de vitesse est paradoxalement un signal positif pour les moteurs alors que nos bandes passantes permettent un chargement plus aisé des contenus. Google pousse aussi à une résolution supérieure des images, qui participent grandement au poids total des pages. Là aussi il faut raison gardée et optimiser le chargement des contenus par optimisation des directives sur la gestion cache du serveur web et du navigateur visiteur (commandes sur .htaccess, ou Apache, paramétrages Nginx..)
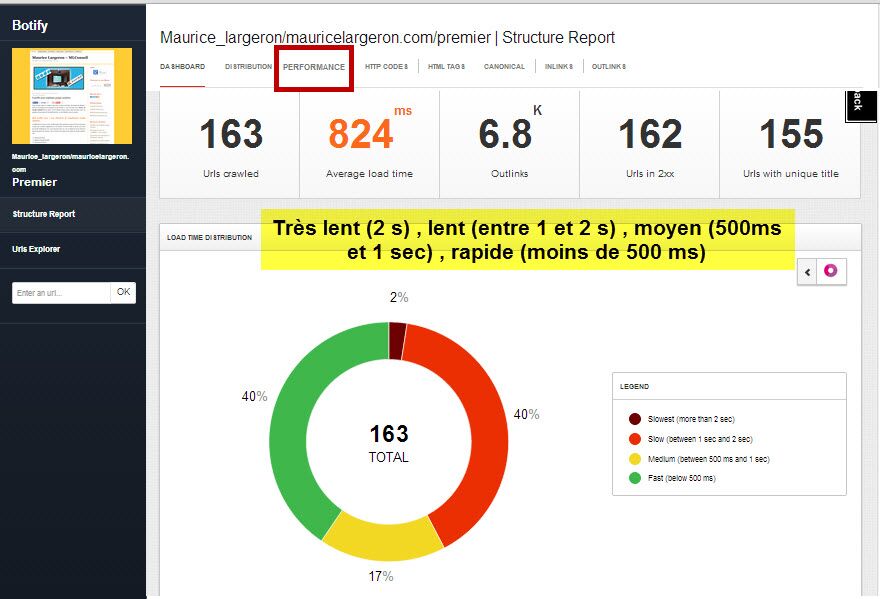
Vitesse de réponses des pages
Un explorateur d’urls complet
Je termine par l’explorateur des urls , un moteur de recherche interne à Botify qui permet de faire des requêtes selon les schémas d’urls, les statistiques , les liens internes/externes, les redirections, les canoniques par des règles de correspondances , ou d’expressions régulières.
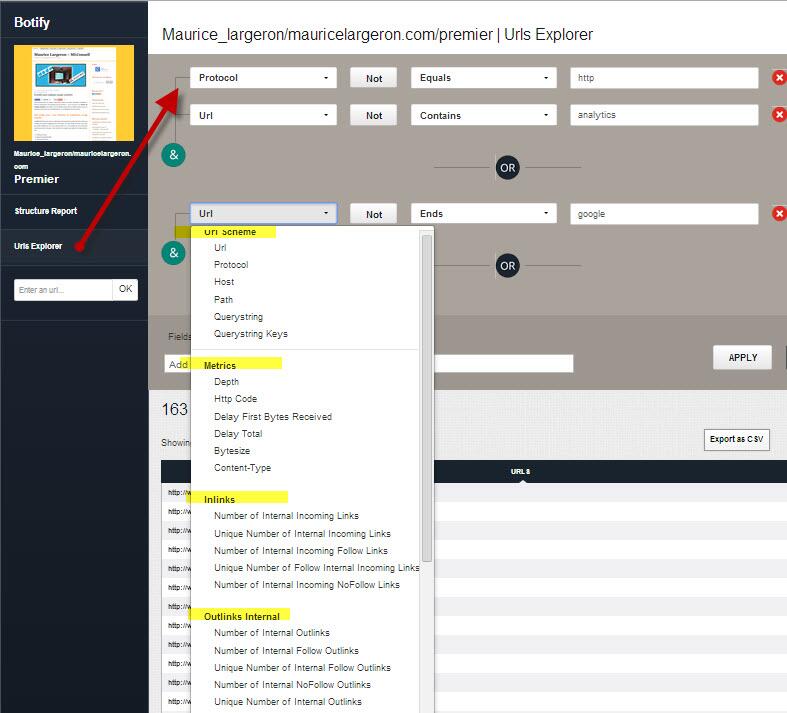
Un explorer puissant sur toute la base collectée
Quelques ressources
- Botify : https://fr.botify.com/
- Watussi : un analyseur de logs gratuit , merci à son créateur Jean Benoît Moingt


